
weeklynote-1
一、 本周工作总结
本周主要是在之前的工作上进一步调研。
- 对端到端自动驾驶的攻击方法再次进行了调研,发现实在是没有新的工作(之前做过这个方向的小组最新的工作也转向了对VLA for AD的对抗攻击)(考虑的是应该型不太通);
- 此外还对基于传统视觉模型和VLM的以补丁和纹理形式的对抗攻击进行了调研。
二、 主要进展
端到端自动驾驶的攻击方法调研
在《Attack End-to-End Autonomous Driving through Module-Wise Noise》中提出的对端到端的攻击方法仅仅只是在模型forward过程中,向每个层的原始输入x添加一个扰动噪声(原文称为对抗噪声),并以模型的最终总的loss
 提升作为攻击指标,而没有设定任何实际的下游任务作为攻击目标。
提升作为攻击指标,而没有设定任何实际的下游任务作为攻击目标。此外,最近关于E2E自动驾驶的研究也多转向其中的一个模块(例如在半反应模拟中根据多传感器数据生成驾驶轨迹等任务),而不再是之前UniAD这样大一统的实现完成所有可能设计的任务。此外之前follow的北航一个博士目前也转向了做对于AD-VLM的对抗攻击。
《Black-Box Adversarial Attack on Vision Language Models for Autonomous Driving》
//TBD
对于传统视觉模型的补丁类型的攻击
《Fooling automated surveillance cameras: adversarial patches to attack person detection》 (AdvPatch)
文章通过优化算法生成一个可打印的物理补丁,旨在让目标检测器(原文攻击目标是YOLOv2)无法识别到人这个类别。其优化目标函数综合考虑了三个方面:
L_obj:最小化检测器输出的物体置信度,让检测器认为补丁区域不存在任何物体。L_nps:不可打印分数,确保生成的补丁颜色能够被普通打印机真实还原。L_tv:总变分损失,使得补丁的颜色过渡平滑,在视觉上不显得突兀。
提出了一种为具有高类内差异性目标(如“人”)生成对抗补丁的方法,旨在让持有该补丁的人能够有效“躲避”自动监控摄像头的检测。实验证明,将优化出的补丁打印在纸板上,在真实世界场景中能够显著降低人体检测器的准确率,这表明了物理世界攻击的可行性。
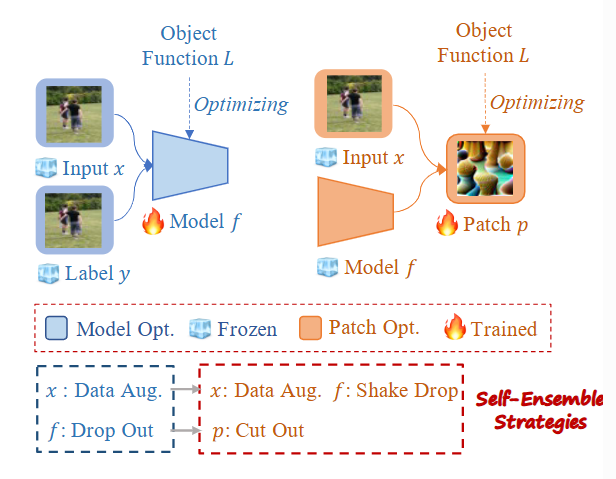
《T-SEA: Transfer-based Self-Ensemble Attack on Object Detection》
针对传统迁移攻击依赖多个模型集成成本高的问题,提出了迁移式自集成攻击,仅使用单个白盒模型即可生成高迁移性的对抗补丁。其核心是借鉴了模型训练中提升泛化性的技巧,提出了三种“自集成”策略:
- 数据自集成:对输入数据进行约束性数据增强。
- 模型自集成:使用
ShakeDrop等方法在模型内部随机丢弃部分层级,虚拟出多个模型变体。 - 补丁自集成:在训练时对补丁本身进行
CutOut(随机遮挡),防止其对特定模型或图像过拟合。
- 聚焦于单模型迁移攻击场景,旨在解决获取和训练多个模型进行集成的困难。通过将补丁优化类比于常规的模型优化过程,论文提出了一系列自集成策略,有效利用有限信息,防止补丁过拟合。实验证明,T-SEA能显著提升在多种主流检测器上的黑盒迁移攻击效果。
VLM 对抗(VLM Adversarial Attacks)
《A Frustratingly Simple Yet Highly Effective Attack Baseline…》(M-Attack)
- 文发现以往攻击在商业闭源VLM上失败的原因是扰动缺乏明确的语义信息。为此,提出了一种极为简洁但高效的M-Attack方法,其核心在于增强扰动的局部语义。具体操作为:在每个优化步骤中,对加入扰动的图片进行随机裁剪和缩放,再将处理后的图片与目标图片在多个代理模型(比如如CLIP)的嵌入空间中进行对齐。这个过程迫使对抗扰动集中在图像的语义核心区域,而不是均匀分布。
- 论文提出的方法通过分析失败的对抗样本,发现缺乏语义信息的均匀扰动是导致商业LVLM攻击失败的关键。于是提出了随机裁剪和缩放策略,能够生成具有局部聚合语义的扰动,极大地提升了对闭源商业模型的迁移攻击能力,在GPT-4.5、GPT-4o等模型上取得了超过90%的成功率。
 提升作为攻击指标,而没有设定任何实际的下游任务作为攻击目标。
提升作为攻击指标,而没有设定任何实际的下游任务作为攻击目标。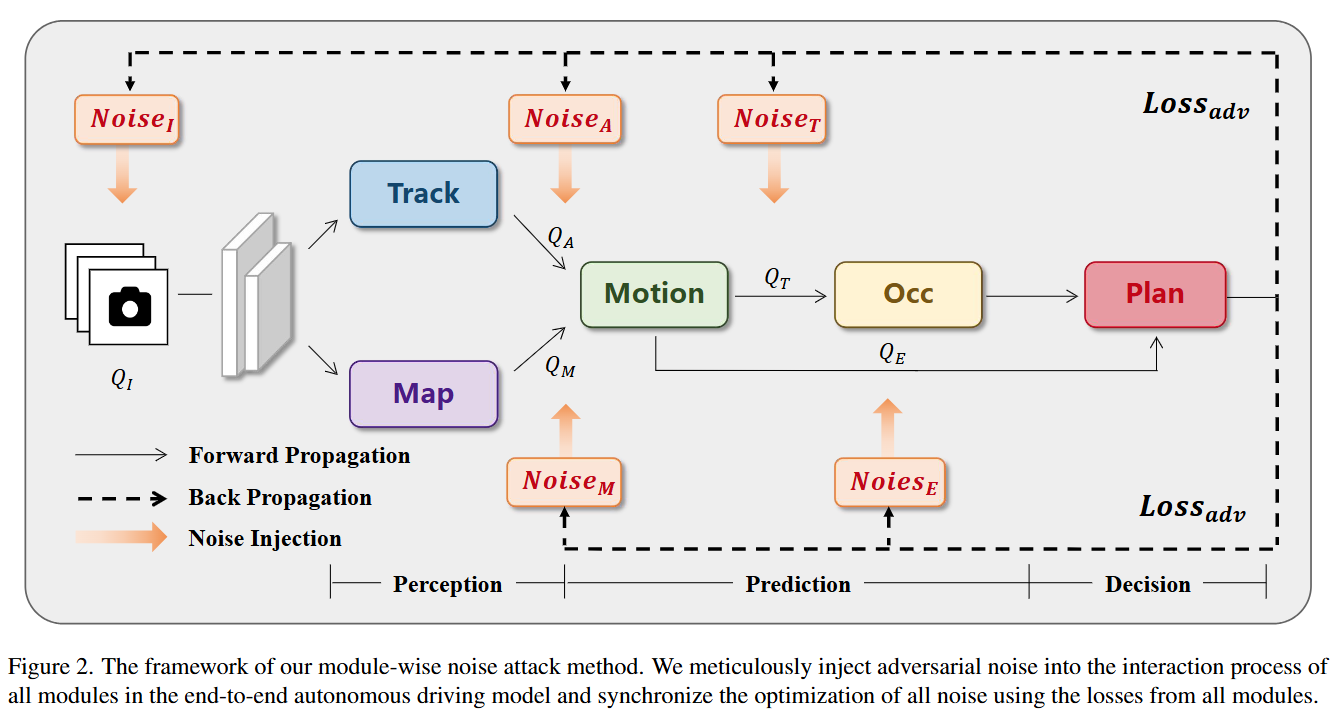
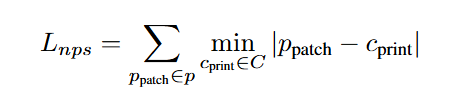
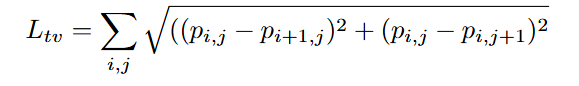
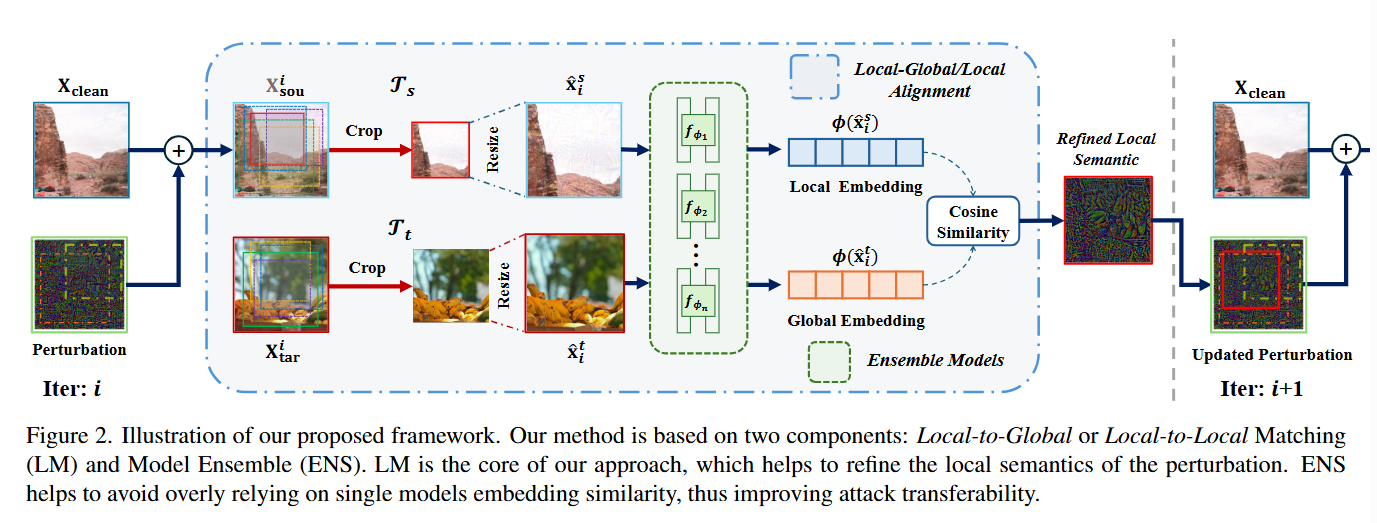
- 《Adversarial Attacks against Closed-Source MLLMs via Feature Optimal Alignment》(FOA-Attack)
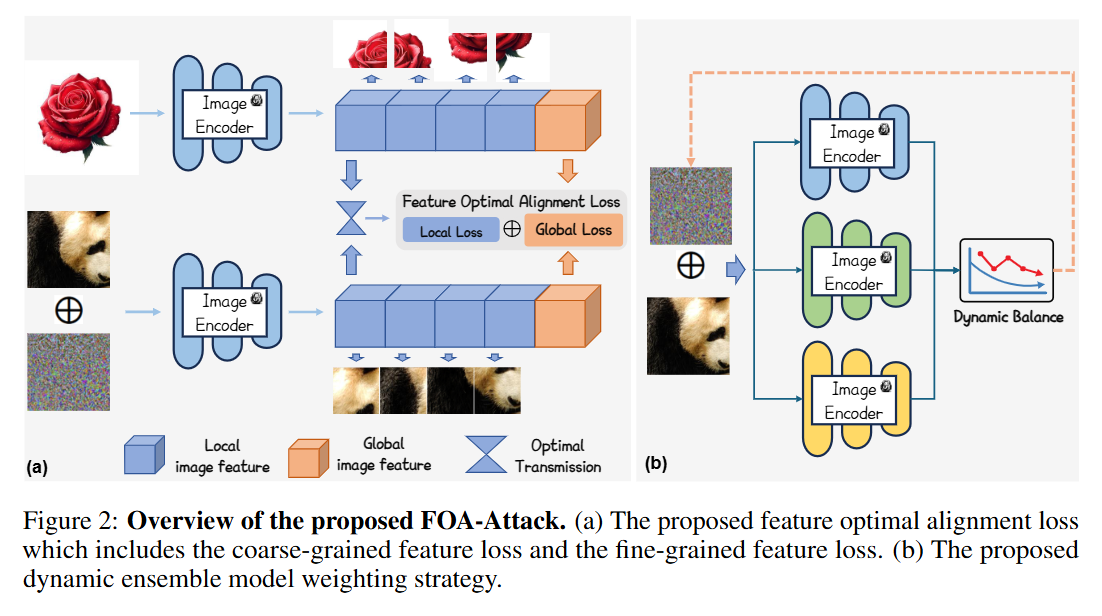
- 核心方法:提出FOA-Attack框架,通过全局与局部特征协同对齐来提升攻击迁移性。
1. 全局对齐:使用`[CLS]`等全局特征向量,通过余弦相似度损失进行粗粒度的语义对齐。
2. 局部对齐:为解决局部特征的冗余性,先通过聚类提取关键的局部模式,然后将不同图片局部特征簇中心的对齐问题建模为最优传输问题,实现细粒度的精准匹配。
3. 动态集成:根据不同代理模型损失的收敛速度,动态调整它们在总损失中的权重。
- 现有攻击方法仅关注全局特征对齐,忽略了丰富的局部信息,导致对闭源MLLM的迁移性不足。FOA-Attack通过全局(粗粒度)和局部(基于聚类和最优传输的细粒度)特征的双重对齐,并结合动态模型加权策略,显著增强了对抗样本的迁移能力,在多种开源及闭源模型上均取得了SOTA效果。
- 《PhysPatch: A Physically Realizable and Transferable Adversarial Patch Attack...》
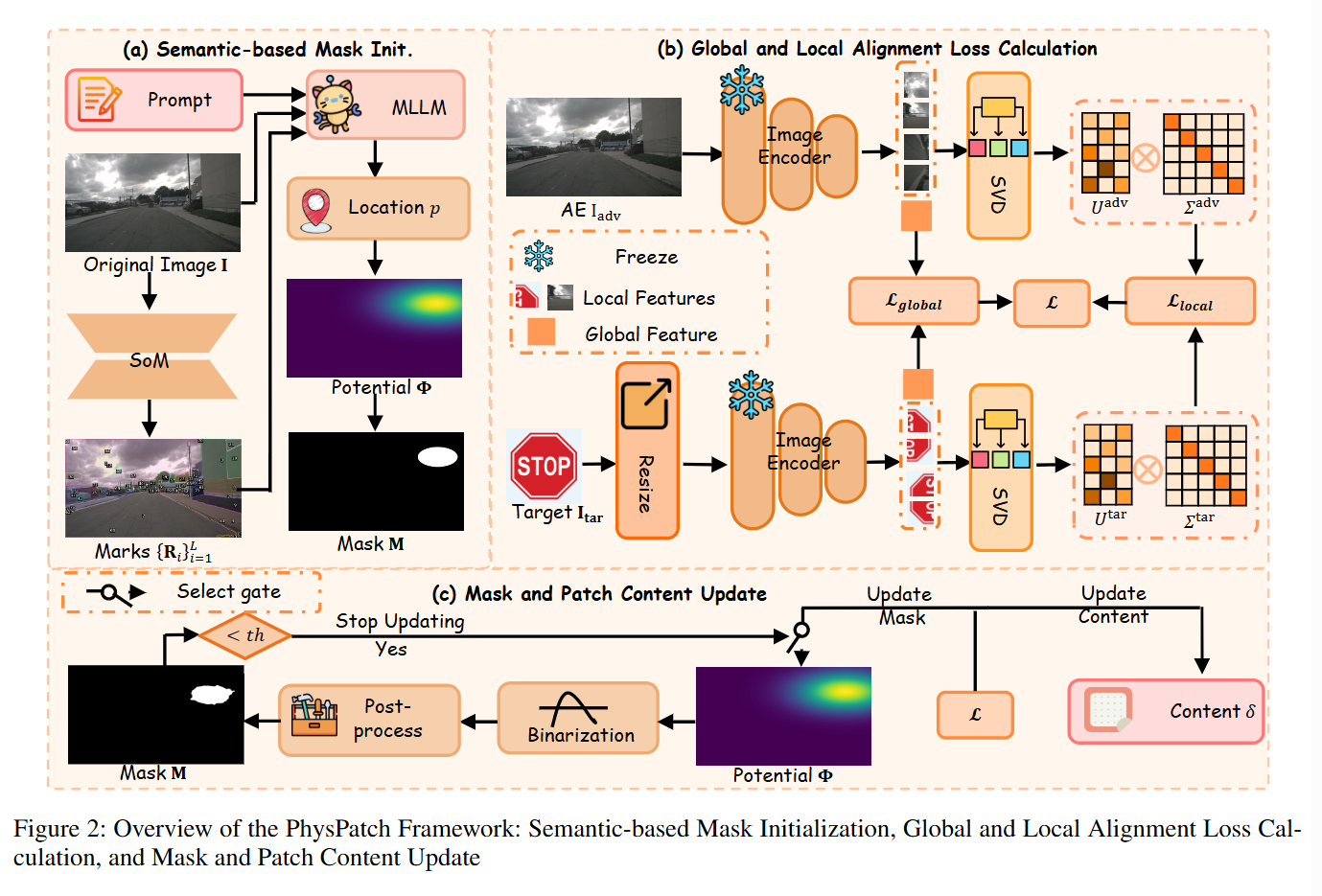
- 提出PhysPatch框架,专门用于生成面向自动驾驶系统中MLLM的物理可实现对抗补丁,它同时优化补丁的位置、形状和内容。
1. 位置与形状:利用MLLM的推理能力进行语义感知的掩码初始化,找到场景中适合粘贴补丁的物理位置(bi如墙面、广告牌),并结合自适应势场更新算法优化补丁的形状,使其更自然。
2. 内容与迁移性:采用SVD对局部特征进行降维压缩和对齐,以增强跨模型的迁移性。同时,提出补丁引导的裁剪-缩放策略,确保在数据增强时,补丁始终位于裁剪框内,避免梯度消失。
- 针对现有补丁攻击在复杂的MLLM AD系统上效果不佳的问题,该论文设计了PhysPatch框架。它通过语义推理来确定物理上可行的补丁位置,并使用基于SVD的局部对齐损失和特殊的裁剪策略来提升攻击的迁移性。实验证明,PhysPatch在多种MLLM(包括商业模型)上表现出色,且生成的补丁在自动驾驶场景中具有很强的物理部署可行性。
三、 研究心得与思考
目前调研的VLM对抗论文在攻击闭源商用模型方面都取得了显著成果,M-Attack和FOA-Attack均报告了对GPT系列、Claude系列、Gemini和字节的豆包系列等模型的成功攻击。PhysPatch和另一篇论文CAD (Cascading Adversarial Disruption) 也成功攻击了用于自动驾驶的VLM,如Dolphins。这些方法的核心趋势是从全局特征匹配转向更精细化的局部语义对齐,通过数据增强、特征工程等方式,成功攻击了商业闭源模型。
仍然存在一些问题:
- 现有的这些方法均未能成功攻击DriveLM模型。
- 传统攻击中还存在有基于纹理的攻击,目前似乎还没看到有将该方法迁移到对于LVLM的攻击上,有待继续调研
四、 下周工作计划
- 阅读一下DriveLM论文,分析其模型架构,尝试从理论上定位其鲁棒性的来源。
- 尝试用M-Attack、FOA-Attack的开源代码,对DriveLM进行攻击复现,分析失败样本的特征。