
一些关于注意力机制和Transformer的Q&A
没啥用的铺垫,可以直接跳到Q&A
先来一张Transformer的结构图:
然后是多头注意力各个部分的tensor形状: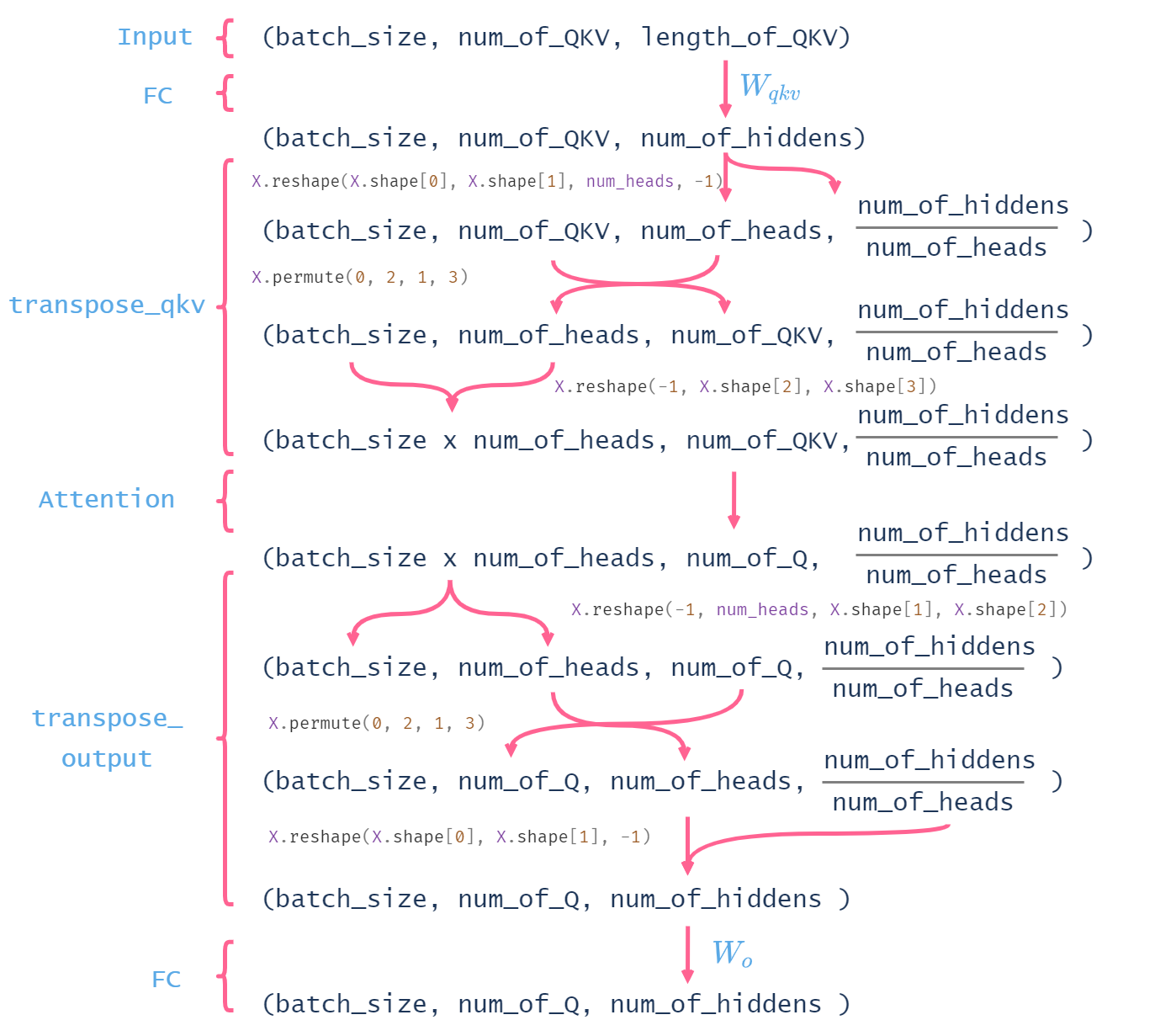
Q&A
Q1: Transformer中Multi-head Attention中每个head为什么要进行降维?
先来看看Multi-head Attention的代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85class MultiHeadAttention(nn.Module):
"""Multi-Head Attention module"""
def __init__(self, n_head, d_model, d_k, d_v, dropout=0.1):
super().__init__()
self.n_head = n_head # 注意力头的数量
self.d_k = d_k # 每个头中K (和Q) 的维度
self.d_v = d_v # 每个头中V 的维度
# 线性投影层:将 d_model 维的输入分别投影,为所有头准备 Q, K, V
# 注意输出维度是 n_head * d_k (或 d_v),这是为了后续可以方便地切分成多个头
self.w_qs = nn.Linear(d_model, n_head * d_k, bias=False)
self.w_ks = nn.Linear(d_model, n_head * d_k, bias=False)
self.w_vs = nn.Linear(d_model, n_head * d_v, bias=False)
# 最终将所有头的输出拼接后,再进行一次线性变换,映射回 d_model 维度
self.fc = nn.Linear(n_head * d_v, d_model, bias=False)
# temperature 通常是 d_k 的平方根,用于缩放点积结果
self.attention = ScaledDotProductAttention(temperature=d_k**0.5)
self.dropout = nn.Dropout(dropout)
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6) # 层归一化
def forward(self, q, k, v, mask=None):
# q, k, v 的输入形状通常是: [batch_size, seq_len, d_model]
# len_q, len_k, len_v 分别是 Q, K, V 序列的长度
# sz_b 是批量大小 (batch_size)
d_k, d_v, n_head = self.d_k, self.d_v, self.n_head
sz_b, len_q, len_k, len_v = q.size(0), q.size(1), k.size(1), v.size(1)
# 保存原始的 q 输入,用于残差连接
residual = q
# 1. 线性投影并为多头重塑 (Dimensionality transformation and reshaping for heads)
# q 的原始输入形状: [sz_b, len_q, d_model]
# self.w_qs(q) 输出形状: [sz_b, len_q, n_head * d_k]
# .view(...) 后 q 的形状: [sz_b, len_q, n_head, d_k]
# 这里的 d_k 就是每个注意力头中 Q 向量的维度。
# 如果 d_k < d_model (通常 d_k = d_model / n_head), 那么对于每个头来说,
# 相对于原始的 d_model,其操作的维度降低了。
q_proj = self.w_qs(q).view(sz_b, len_q, n_head, d_k)
k_proj = self.w_ks(k).view(sz_b, len_k, n_head, d_k)
v_proj = self.w_vs(v).view(sz_b, len_v, n_head, d_v)
# 2. 调整维度顺序以适应注意力计算
# 将 n_head 维度提前,使得每个头可以并行计算
# q_proj 形状从 [sz_b, len_q, n_head, d_k] 变为 [sz_b, n_head, len_q, d_k]
q_proj = q_proj.transpose(1, 2)
k_proj = k_proj.transpose(1, 2)
v_proj = v_proj.transpose(1, 2)
# 3. 处理掩码 (mask)
if mask is not None:
# mask 通常形状是 [sz_b, len_q, len_k] 或 [sz_b, 1, len_k] (自注意力)
# unsqueeze(1) 是为了使其能广播到每个头上: [sz_b, 1, len_q, len_k]
mask = mask.unsqueeze(1)
# 4. 执行缩放点积注意力
# q_proj (输入): [sz_b, n_head, len_q, d_k]
# k_proj (输入): [sz_b, n_head, len_k, d_k]
# v_proj (输入): [sz_b, n_head, len_v, d_v] (注意 len_k == len_v)
# attention_output (输出): [sz_b, n_head, len_q, d_v]
# attn_weights (注意力权重): [sz_b, n_head, len_q, len_k]
attention_output, attn_weights = self.attention(q_proj, k_proj, v_proj, mask=mask)
# 5. 拼接多头输出并进行最终线性变换
# attention_output 形状: [sz_b, n_head, len_q, d_v]
# transpose(1, 2) 后形状: [sz_b, len_q, n_head, d_v]
# .contiguous() 确保内存连续,以便 .view() 操作
# .view(sz_b, len_q, -1) 将最后两维 (n_head, d_v) 合并为一维 n_head * d_v
# 形状变为: [sz_b, len_q, n_head * d_v]
# 这里是将所有头的输出在最后一个维度上拼接起来。
concat_output = attention_output.transpose(1, 2).contiguous().view(sz_b, len_q, -1)
# self.fc 将 [sz_b, len_q, n_head * d_v] 映射回 [sz_b, len_q, d_model]
final_output = self.dropout(self.fc(concat_output))
# 6. 残差连接和层归一化
final_output += residual
final_output = self.layer_norm(final_output)
return final_output, attn_weights
对head的“降维”操作主要发生在步骤1,即线性投影和重塑阶段:1
2
3self.w_qs = nn.Linear(d_model, n_head * d_k, bias=False)
...
q_proj = self.w_qs(q).view(sz_b, len_q, n_head, d_k)
例如,当$d_{model} = 512, n_{head}$ = 8时,$d_k$和$d_v$通常会被设置为$512 / 8 = 64$,.view(...)操作将线性层得到的$ 512 $维的向量(对于序列中的每个token)解释为$ 8 $个$ 64 $维的向量,分别对应$ 8 $个注意力头。于是,每个注意力头在计算注意力时,实际操作的是$ 64 $维的$Q, K, V$向量,而不是原始的$ 512 $维。
下面摘抄一段李沐老师引入多头注意力的文案:
当给定相同的查询、键和值的集合时, 我们希望模型可以基于相同的注意力机制学习到不同的行为, 然后将不同的行为作为知识组合起来,捕获序列内各种范围的依赖关系 (例如,短距离依赖和长距离依赖关系)。因此,允许注意力机制组合使用查询、键和值的不同子空间表示(representation subspaces)可能是有益的。
这样,我们就不难总结出如下的结论:
- 使每个头关注不同子空间的信息:通过将$d_{model}$分成多个头的子空间($d_k$和$d_v$),每个头有机会学习输入特征的不同线性组合,从而关注输入的不同方面或“子空间表示”,进而增加模型的表达能力和效率。
- 减少计算复杂度:注意力计算的核心是$Q$和$K$的点积。如果不降维的话,原始的缩放点积注意力的时间复杂度是$O(d^2)$,其中$d$是输入向量的维度,再加上多头注意力的想法,则时间复杂度进一步来到$O(n \times d^2)$,其中$n$是头的数量。而通过降维到$d_k$和$d_v$,可以在保持较高的表达能力的同时,大大减少计算复杂度到$O(n \times d_k^2)$。此外在这里有一个工程上的
trick,为了加速代码用了并行的写法,大致可以理解为是把所有注意力头里面的参数拼起来, 变成了一个大的全连接层。
Q2:Transformer的点积模型做缩放的原因是什么?为什么缩放因子是$\sqrt(d_k)$?
Transformer中的缩放点积注意力计算公式为:
我们可以认为$Q$和$K$的元素是从均值为0,方差为1的正态分布中采样的(因为qkv在上一层中进行layer norm后得到的)。那么$q$和$k$的点积$QK^T$的方差为$d_k$:
因此可以大致认为内积之后、softmax之前的数值在$[-3\sqrt{d}, 3\sqrt{d}]$这个范围内,以上文为例,$d_k = 64$,则softmax时两个边界值分别是$e^{-24}$和$e^{24}$,因此经过softmax之后,Attention的分布非常接近一个one hot分布了,这带来严重的梯度消失问题,导致训练效果差。
因此需要缩放因子$\sqrt{d_k}$来平衡点积的大小,使得softmax的输入值不会过大或过小,从而避免梯度消失问题。选择缩放因子$\sqrt{d_k}$刚好可以将点积后的结果归一化成均值为0,方差为1的向量。
Q3:为什么要添加位置编码,介绍一下各类位置编码。
Transformer中Encoder部分会对输入的token进行自注意力操作,在不添加额外的位置编码时,自注意力操作是具有轮换对称性的,即任意给定两个token $[x_i, x_j]$,对应的表征向量为 $[e_i, e_j]$,对于注意力操作函数$f$,任意交换$x_i, x_j$的次序,期望下交换是具有不变性,即:
换句话说就是,你喂给模型“猫爱吃鱼”和“鱼爱吃猫”这两句话大概率会得到一样的输出,这显然与我们对大模型的预期不符(其应当同时具备句法知识和世界知识,这里的例子表明无法学习到世界知识?对吗),因此需要添加位置编码来打破这种对称性。
可以根据位置编码的思想将位置编码分为两类:
- 绝对位置编码:为输入序列中的每个绝对位置生成一个特定的编码,并将其直接融入到该位置的词向量表征中。模型直接感知每个词在序列中的确切位置。
- 训练式:直接将位置编码当作可训练参数,比如最大长度为512,编码维度为768,那么就初始化一个512×768的矩阵作为位置向量,让它随着训练过程更新。对于这种训练式的绝对位置编码,一般的认为它的缺点是没有外推性,即如果预训练最大长度为512的话,那么最多就只能处理长度为512的句子,再长就处理不了了。
- 三角式:最知名的是Google的论文《Attention is all you need》中提出的Sinusoidal位置编码,使用正弦和余弦函数生成位置编码,具体公式为:其中$p{k,2 i}, p{k, 2 i+1}$分别是位置k的编码向量的第$2i, 2i+1$个分量,$d$是向量维度。
至于这种编码方式能否满足前面我们提到的同时能表示绝对位置信息和相对位置信息的要求,苏神在他的《Sinusoidal位置编码追根溯源》中有证明。
- 相对位置编码:模型关注的是序列中元素之间的相对位置关系,通常通过在注意力机制中引入表示相对位置的可学习参数或动态计算的偏差来实现,使模型能够根据词与词之间的距离来调整它们之间的交互。
- 经典式
- XLNET式
- T5式
- 融合编码
集大成者- RoPE
- ReRoPE
后记
贴一个苏神的《Transformer升级之路》系列的笔记列表,苏神很多文章把数学和论文思想结合的很好,很推荐看:
- Sinusoidal位置编码追根溯源 -> 证明了Sinusoidal位置编码是一种能够表示绝对位置信息和相对位置信息的编码方式
- 博采众长的旋转式位置编码
- 从Performer到线性Attention
- 二维位置的旋转式位置编码
- 作为无限维的线性Attention
- 旋转位置编码的完备性分析
- 长度外推性与局部注意力
- 长度外推性与位置鲁棒性
- 一种全局长度外推的新思路
- RoPE是一种β进制编码
- 将β进制位置进行到底
- 无限外推的ReRoPE?
- 逆用Leaky ReRoPE
- 当HWFA遇见ReRoPE
- Key归一化助力长度外推
- “复盘”长度外推技术
- 多模态位置编码的简单思考
- RoPE的底数选择原则
- 第二类旋转位置编码
- MLA究竟好在哪里?